Reinforcement Learning in Self-Driving Cars
Introduction
Imagine a world where cars can drive themselves, safely maneuvering through city streets, highways, and even busy intersections—all without any input from a human. It’s not sci-fi. It’s the rapidly emerging reality of self-driving cars. But what is it that powers those driving machines? At their core, self-driving cars are designed using a sophisticated form of artificial intelligence (AI) known as reinforcement learning—a technique that allows the AI within a car to learn how to drive just as you and I do: through repeated practice and feedback from failures.
When you learn to drive a car, you get on the road and practice—correcting errors and fine-tuning your skills until your driving becomes second nature. In much the same way, an AI in a self-driving vehicle can also learn by trial and error—performing actions repeatedly in a dynamic world, receiving rewards for successes (i.e., staying on the road) or penalties for failures (i.e., running off the road). An AI in a car learns not to repeat mistakes because if an action leads to an undesirable outcome it receives fewer rewards or more penalties.
In this blog post we’re going to look at how reinforcement learning will shape our future when it comes to self-driving cars—what we’re doing specifically at Waymo technologically speaking, what challenges we face along the way in developing these kinds of AIs, and how close we may be from living in a world where everyone drives alongside robots!

What is Reinforcement Learning?
At its most basic, reinforcement learning (RL) is a way for machines to learn from experience. Picture yourself teaching a child to ride a bike. When they pedal and balance correctly, they experience the joy of forward motion—that’s positive reinforcement. When they fall or veer off course, they know something went wrong—that’s negative reinforcement. With time and practice, the child learns how to balance better by doing, failing, and discovering different outcomes. Reinforcement learning does essentially this same process—but it uses a computer program (an agent) instead of a child, and self-driving car on-roads as an environment instead of a bicycle path.
In RL, the car interacts with its environment: roads, traffic lights, other cars. Every action the car makes (speeding up, slowing down, turning) leads to a reward (positive or negative). The car gets rewards for “good” actions (for example, remaining in its lane) and penalties for “bad” ones (getting too close to another vehicle).
How Reinforcement Learning is Applied in Self-Driving Cars
Reinforcement learning (RL) plays a crucial role in helping self-driving cars make decisions in real time. When a car is on the road, it constantly faces choices: Should it speed up to pass a slower vehicle, slow down to avoid an obstacle, or change lanes? These decisions need to happen quickly and accurately. In RL, the car learns how to make these choices by running thousands of simulations in which it experiences different driving conditions, such as heavy traffic, poor weather, or construction zones.
One of the most popular models used in this learning process is the Deep Q-Network (DQN). This model helps the car understand complex driving environments by learning which actions lead to the best long-term outcomes. For instance, in a simulation, the car might learn that staying behind the car might learn that staying behind a slow vehicle might be safer in certain conditions, even though overtaking could save time. Through trial and error, the car starts to “remember” which decisions result in the safest and most efficient driving behaviors.
Self-driving car companies like Waymo and Tesla use simulators — virtual driving environments — to train their vehicles safely. These simulators allow cars to face millions of possible driving scenarios without risking real-world accidents. Just as pilots practice in flight simulators, self-driving cars “practice” driving in these controlled environments. Once they perform well in simulation, they’re ready to be tested on actual roads.
Comprehending Deep Q-Networks (DQN) within the Context of Self-Driving Cars
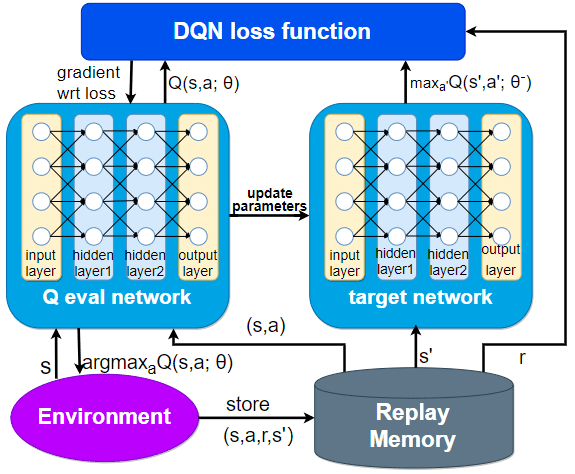
A Deep Q-Network (DQN) combines traditional Q-learning with deep neural networks to help self-driving cars handle real-world driving conditions. In traditional Q-learning, an agent (the car) uses an action-reward table to decide its next move. However, real-world driving is too complex for a simple table, as there are far too many possible scenarios. This is where deep learning becomes essential.
With DQN, the car doesn't have to store every possible action and outcome. Instead, it uses a neural network to predict Q-values (the expected reward for each action) based on raw input data from its sensors. This data could include camera images, LIDAR signals, and other environmental data. The neural network processes this information through layers of neurons that help the car recognize important features like stop signs, lane markings, or other vehicles. Based on this, the car can predict the best action to take in a given situation.
DQNs allow self-driving cars to make more informed decisions in complex environments and improve over time by learning from past mistakes. The ability to handle high-dimensional data and make predictions on the fly is what makes DQNs so powerful in autonomous driving systems.
Challenges of Using Reinforcement Learning in Real-World Driving
While Deep Q-Networks and reinforcement learning have shown great promise in simulations, applying them to real-world driving comes with significant challenges. One major issue is the unpredictability of real-world environments. Unlike the controlled conditions of a simulator, roads are full of unexpected situations: a pedestrian might suddenly step into the street, or a car might behave erratically. This kind of unpredictability makes it hard for self-driving cars to rely solely on reinforcement learning, which typically requires many trial-and-error experiences to master tasks.
Another challenge is the need for extensive training data. Self-driving cars must experience a vast number of diverse driving scenarios to become reliable in real-world conditions. While simulators can provide these experiences safely, the transition from simulation to real-world driving isn’t always seamless. A car might perform well in a simulator but face difficulties when encountering new or rare situations on the road. To overcome this, researchers are constantly refining reinforcement learning models to help cars adapt better to the unpredictable nature of real-world driving.
Moreover, safety is a critical concern. Since reinforcement learning involves learning from mistakes, it’s not always feasible to allow self-driving cars to “learn” from real-world errors. For example, if a car incorrectly runs a red light in a simulator, the consequences are minimal. But in the real world, such mistakes could lead to accidents. This makes reinforcement learning in self-driving cars a delicate balance between improving the model through trial and error while ensuring safety at all times.
The Future of Reinforcement Learning in Autonomous Vehicles
The future of the self-driving car will obviously depend on further enhancements of reinforcement learning (RL) techniques since they are key in autonomously driving cars. Despite the efficacy of models like Deep Q-Networks, there are efforts to improve those systems for practical applications that are more effective and reliable. Sim-to-real transfer is one interesting direction that aims to enhance the use of simulations by self-driving cars in real-world situations. This focuses on how to improve the methods by which simulation is made more realistic and helps deep learning systems cope well with unexpected challenges on the road.
Another direction of development is focusing on hybrid learning strategies, in particular where reinforcement learning is combined with other AI methods like supervised learning to create more optimal models. Some hybrid systems are able to use past driving data to predict rare or hazardous events and prepare the vehicle to respond efficiently. This combination of techniques is expected to pave the way for a new generation of self-driving vehicles that are highly efficient even when operating in complex environments.
Real-time decision making has also been earmarked for further research. As computational power continues to increase, cars will be able to process sensor data and drive using that data in near real-time, even within milliseconds, improving safety and responsiveness in rapidly changing situations.